Ce qu’il faut retenir
- Les solutions RAG et de vectorisation classiques échouent pour la documentation WordPress en raison d’une maintenance fastidieuse, d’une lecture partielle par le LLM et d’une perte de contexte essentiel comme les hooks et la hiérarchie des templates.
- J’ai créé une solution propriétaire combinant MCP (Model Context Protocol), un parsing intelligent générant des fichiers JSON structurés, et l’agent conversationnel Dust, formant une architecture « toile d’araignée » qui expose l’ensemble du projet WordPress (fichiers, classes, fonctions, hooks) de façon exploitable.
- Les tests réels montrent que ce système fournit une analyse précise et instantanée (vue d’ensemble, CPT, blocs Gutenberg, dépendances, hooks) sans limite de taille ni perte d’information, avec des réponses factuelles référencées et une mémoire collaborative via Markdown.
Résumé généré par IA
RÉSUMÉ : Après avoir testé beaucoup de solutions du marché (RAG, LLM locaux, Dify.ai, vectorisation), j’ai créé ma propre documentation interactive WordPress combinant MCP custom, parsing intelligent en JSON et agent Dust. Ce système analyse automatiquement thèmes et plugins WordPress pour générer une vue d’ensemble exploitable via un LLM, avec accès aux hooks, fonctions, classes et contenu des fichiers à la demande. Résultat : une analyse projet précise sans limite de taille ni perte d’information.
Table des matières
- Le problème des solutions existantes pour documenter WordPress
- Pourquoi le RAG classique ne fonctionne pas
- Mon test avec Dify.ai et Ollama
- La solution : MCP + parsing intelligent + Dust
- Architecture en toile d’araignée
- Les fichiers JSON générés automatiquement
- Intégration MCP et agent Dust
- Résultats et tests en conditions réelles
Tu connais ce sentiment quand tu cherches l’outil parfait pour créer une documentation interactive et qu’il n’existe tout simplement pas ? C’est exactement ce qui m’est arrivé après des mois de tests infructueux.
J’avais déjà publié un article sur l’analyse rapide de projets WordPress, mais soyons honnêtes : c’était vraiment trop rapide et souvent pas assez pertinent selon les cas d’usage.
Le problème des solutions existantes pour documenter WordPress
J’ai passé des semaines à tester toutes les approches possibles pour créer une documentation interactive WordPress efficace :
- Applications de RAG (Retrieval-Augmented Generation)
- LLM hébergés localement avec Ollama
- Lecture de fichiers globaux versus multiples
- Bases de données vectorielles
- Solutions cloud
Le bilan ? Aucune solution ne m’a vraiment convaincu pour une analyse complète de projets WordPress. Et c’est là que je me suis dit : si ça n’existe pas, autant le créer.

Pourquoi le RAG classique ne fonctionne pas pour WordPress
Les applications de RAG pour une documentation interactive WordPress, c’est théoriquement l’idéal. Mais en pratique, c’est un enfer :
Les 3 problèmes majeurs du RAG pour WordPress que j’ai rencontré
- Maintenance cauchemardesque : Tu dois envoyer tout ton projet, fichier par fichier, puis le maintenir à jour à chaque modification. Pour un thème avec +1K fichiers, imagine le travail.
- Lecture partielle du LLM : Même avec tous les fichiers envoyés, le LLM lit 2-3 fichiers maximum (10 s’il est motivé) puis décide qu’il a assez d’informations. Résultat : des réponses partielles et incomplètes.
- Vectorisation qui masque l’information : La transformation en vecteurs fait perdre du contexte crucial pour comprendre la structure WordPress (hooks, actions, filtres, architecture MVC).
Mon test avec Dify.ai et Ollama pour la documentation WordPress
Je me suis dit qu’en local avec Ollama, j’allais pouvoir créer une documentation interactive WordPress optimale. En cherchant, je découvre Dify.ai, une solution prometteuse qu’on peut containériser (avec Docker).
Configuration de Dify.ai pour WordPress
Voici ce que j’ai mis en place :
- Configuration Docker Dify et Ollama desktop
- Connexion d’un modèle LLM téléchargé localement
- Création d’agents avec accès aux fichiers
- Intégration d’une base de données vectorielle
- Script Python pour automatiser l’envoi des fichiers à chaque modification
Le système vectorise et regroupe automatiquement les informations du projet WordPress. Ça a l’air parfait sur le papier.
Le problème de pertinence
Ça marche… mais la pertinence n’est pas au rendez-vous pour une vraie documentation interactive. La vectorisation ici n’est pas la bonne solution, on perds des points importants : les relations entre hooks WordPress, la hiérarchie des templates, les dépendances entre fonctions. (en soit tout ce que j’ai dit juste au dessus sur le RAG)
C’est excellent pour un second cerveau personnel, mais insuffisant pour documenter un projet WordPress professionnel.
La solution : MCP + parsing intelligent + Dust
Après plusieurs jours de réflexion, j’ai eu le déclic : combiner trois technologies pour créer une vraie documentation interactive WordPress.
Les 3 piliers de ma solution
- MCP (Model Context Protocol) : Un serveur custom en PHP (pour fonctionner avec Dust) qui expose les données du projet via le protocole MCP
- Parsing intelligent : Analyse complète du projet WordPress avec génération de fichiers JSON structurés
- Agent Dust : Interface conversationnelle connectée au MCP pour interroger la documentation interactive WordPress
Spoiler : Ma documentation interactive WordPress fonctionne et mes collègues la testent actuellement.
Objectifs de la documentation interactive WordPress
Via un LLM Dust, pouvoir interagir avec n’importe quel projet WordPress (thème ou plugin) et obtenir :
- Une vue d’ensemble complète de l’architecture
- La structure technique (MVC, procédurale, orientée objet)
- L’inventaire des dépendances et librairies
- Le support multilingue et internationalisation
- La liste complète des hooks WordPress utilisés
- L’analyse des Custom Post Types et taxonomies
- La cartographie des blocs Gutenberg
- etc.
Architecture en toile d’araignée pour WordPress
J’ai retourné le problème dans tous les sens pour aboutir à une architecture que j’appelle « toile d’araignée 🕸️ » (le nom est nul mais j’ai pas mieux) pour ma documentation interactive WordPress.
Le principe du parsing intelligent WordPress
Parser intégralement un projet WordPress (thème ou plugin) et analyser automatiquement :
- Tous les hooks WordPress (actions et filtres)
- Le code PHP (classes, méthodes, fonctions)
- Le code CSS et JavaScript
- La structure complète des dossiers
- Les templates et hiérarchie WordPress
- Les fichiers de configuration
Pour générer des fichiers JSON structurés plus simples à lire et interroger qu’un fichier texte brut.
Les fichiers JSON générés automatiquement
Ma documentation interactive génère plusieurs fichiers JSON optimisés pour l’interrogation par un LLM.
1. Vue globale du projet WordPress
Un fichier JSON qui recense chaque fichier avec ses métadonnées complètes :
{
"name": "FooterOptionsFields.php",
"relativePath": "wp-content/themes/TEST/app/ACF/Fields/Options/FooterOptionsFields.php",
"size": 1869,
"extension": "php"
}Le tout organisé par thème, dossier et plugin avec un sommaire global :
{
"filesScanned": 969,
"summary": {
"themes": {
"subcategories": 4,
"files": 947
},
"plugins": {
"subcategories": 3,
"files": 10
},
"other": {
"subcategories": 1,
"files": 12
}
}
}Leçon importante pour les projets : Bien nommer ses fichiers, dossiers et fonctions devient absolument capital pour la documentation interactive. Le LLM s’appuie énormément sur ces noms pour comprendre l’architecture.
2. Analyse complète des hooks WordPress
Des statistiques qui donnent immédiatement une idée de la complexité du projet WordPress :
{
"stats": {
"globalFunctions": 160,
"classMethods": 756,
"totalHooks": 354,
"hooksByType": {
"add_action": 75,
"add_filter": 173,
"do_action": 7,
"apply_filters": 99
},
"filesWithGlobalFunctions": 84,
"filesWithClasses": 207,
"filesWithHooks": 118,
"totalFiles": 347
}
}Puis le détail de chaque hook WordPress avec son contexte complet :
{
"type": "add_action",
"hook": "wp_head",
"callback": "whodunit_imagify_support_wp_head",
"priority": null,
"args": null,
"file": "wp-content/plugins/imagify-support/imagify-support.php",
"line": 12
}Les hooks sont également regroupés par fichier pour faciliter la navigation :
{
"file": "wp-content/themes/TEST/app/inc/config/body-class.php",
"hooks": [
{
"type": "add_filter",
"hook": "body_class",
"callback": "function() { /* anonymous */ }",
"line": 7
}
]
}Cette structure permet de comprendre rapidement quels fichiers gèrent quels aspects du projet. Note : les fonctions anonymes limitent l’information, d’où l’importance de nommer explicitement les callbacks. (heureusement le nom du hook donne de l’information)
3. Catalogue des structures de code WordPress
Un fichier qui inventorie toutes les méthodes, fonctions et classes présentes dans chaque fichier du projet WordPress. Une cartographie complète qui permet à la documentation interactive WordPress de répondre à des questions comme :
- « Où est définie la classe ProductController ? »
- « Quelles fonctions gèrent l’envoi d’emails ? »
- « Quels fichiers contiennent des requêtes SQL custom ? »
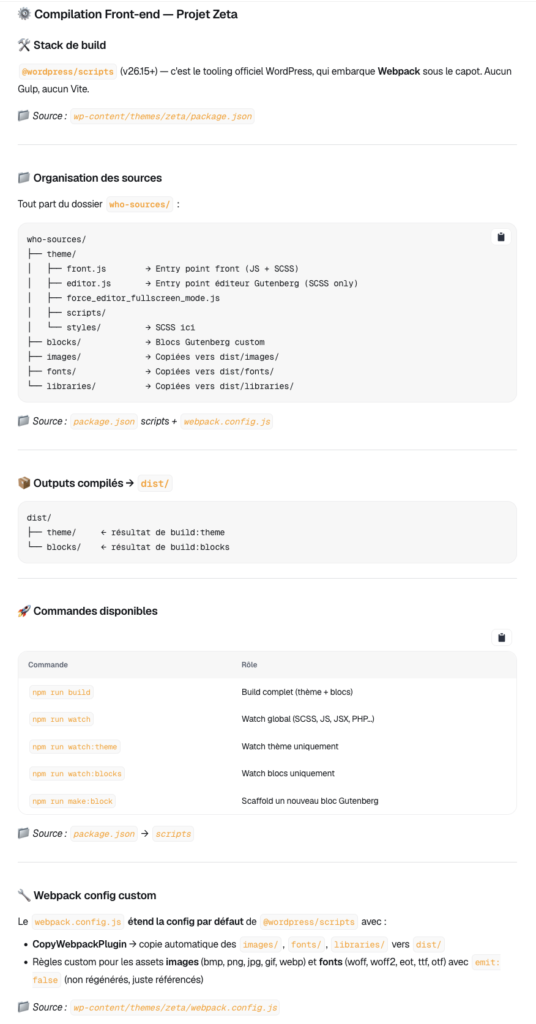
Intégration MCP et agent Dust
Pour transformer ces fichiers JSON en vraie documentation interactive, j’ai développé un serveur MCP custom et configuré un agent Dust.
Le serveur MCP custom pour WordPress
J’ai créé un serveur MCP (Model Context Protocol) en PHP avec communication HTTP pour l’intégration Dust. Ce serveur expose plusieurs outils :
- Vérification projet WordPress : Valide que le dossier contient bien un projet
- Envoi fichiers JSON : Transmet les fichiers d’analyse au LLM de manière optimisée
- Contrôle de poids : Gère intelligemment les gros fichiers avec pagination automatique
- Accès contenu fichiers : Fournit le contenu complet des fichiers WordPress à la demande
- Concaténation intelligente : Assemble plusieurs fichiers en gérant les limites de tokens
- Gestion mémoire partagée : Crée et modifie un fichier Markdown de documentation contextuelle
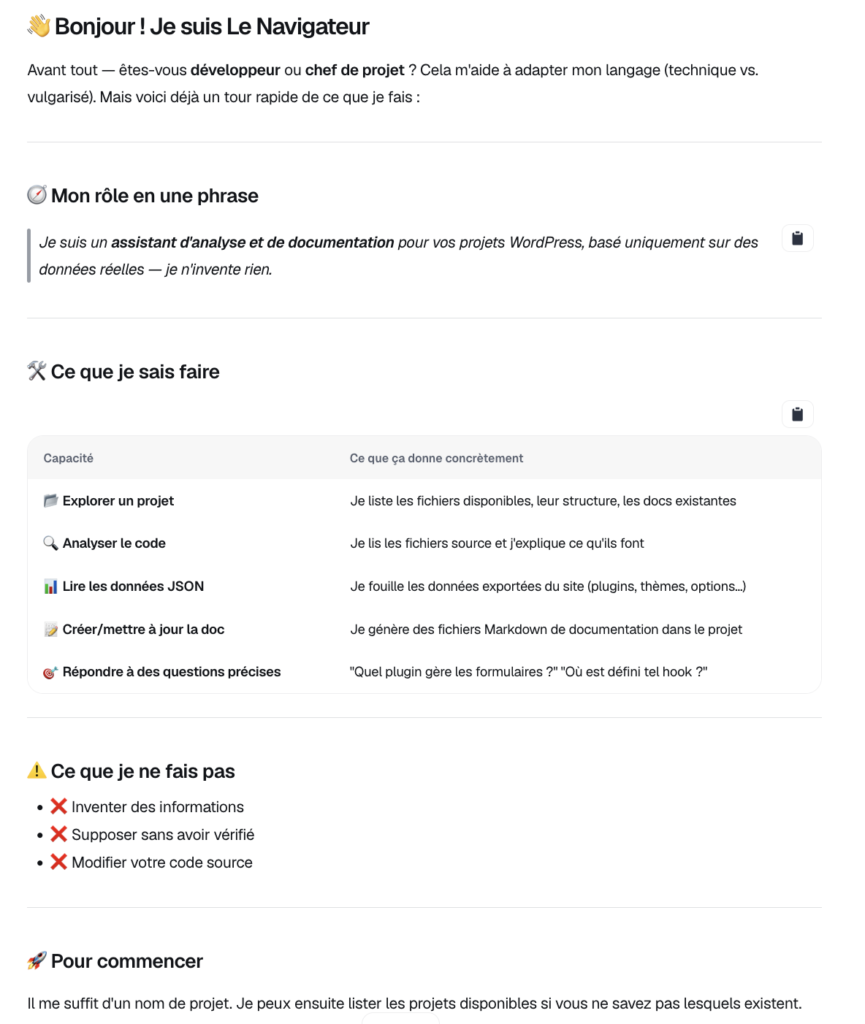
Configuration de l’agent Dust pour WordPress
J’ai créé un agent Dust spécialisé dans la documentation interactive WordPress avec un prompt simple :
Rôle : Documentation interactive WordPress
Mission : Aider à naviguer et comprendre les projets WordPress en se basant exclusivement sur des données factuelles issues du MCP
Règles : Pas d’invention, pas d’extrapolation, juste des faits. Pas de recherche internet. Si pas de réponse trouvée : le dire clairement.
Sources : Uniquement les fichiers JSON d’analyse et le contenu des fichiers du projet accessibles via MCP
Cette configuration garantit que la documentation interactive WordPress reste 100% factuelle et traçable.
Bon ok, évidemment, j’ai donné la possibilité d’avoir des réponses orienté technique et orienté chef.fe de projets.
Comment le LLM utilise le MCP
Grâce à notre toile d’araignée de fichiers JSON, le LLM peut :
- Consulter la vue globale pour identifier les fichiers pertinents
- Analyser les hooks WordPress pour comprendre les interactions
- Demander le contenu spécifique de 2-3 fichiers ciblés
- Obtenir une réponse précise sans surcharge de contexte
Si la concaténation de fichiers devient trop lourde, l’outil MCP prévient le LLM qui peut alors affiner sa demande. C’est toute la puissance de cette documentation interactive WordPress.
Résultats et tests en conditions réelles
Après des semaines de développement, le moment de vérité : tester la documentation interactive WordPress sur de vrais projets clients.
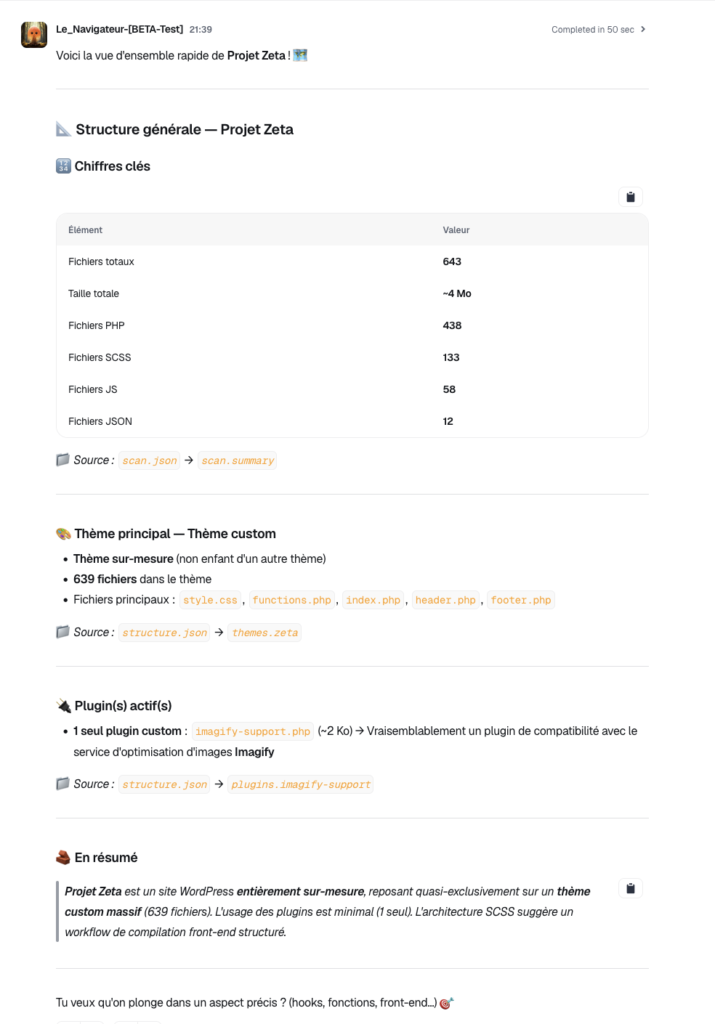
Premier test : analyse d’un thème WordPress complexe
J’ai lancé l’agent Dust sur un thème WordPress de 969 fichiers avec architecture MVC custom. Voici ce que j’ai pu obtenir instantanément :
- Vue d’ensemble complète de l’architecture en 10 secondes
- Liste de tous les Custom Post Types avec leurs fichiers de définition
- Inventaire des 24 blocs Gutenberg custom avec leur localisation exacte
- Analyse des hooks WordPress (354 hooks détectés et documentés)
- Identification des dépendances (ACF, WooCommerce, Polylang)
- Cartographie complète des templates avec hiérarchie WordPress
Franchement, je suis moi-même impressionné. L’agent utilise tous les outils du MCP de manière autonome et intelligente. Il navigue dans le projet WordPress, analyse ce dont il a besoin, et répond avec une précision chirurgicale.
Le bonus inattendu : la mémoire partagée
J’ai ajouté un outil au MCP permettant de créer et modifier un fichier Markdown via conversation. Cette documentation contextuelle permet de noter :
- Pourquoi telle fonctionnalité WordPress a été développée custom
- Demandes spécifiques du client (ex : « Le CPT ‘projets’ ne doit jamais être supprimé, c’est lié à la compta »)
- Contexte (décision) métier non visible dans le code
- Décisions d’architecture et leurs raisons
Toute l’équipe accède à ces infos via la documentation interactive et peut les enrichir. Une vraie mémoire collective qui évolue avec le projet.
Cas d’usage concrets de la documentation interactive WordPress
Voici des questions réelles posées à l’agent avec succès :
- « Où sont définis les Custom Post Types et quels champs ACF sont associés ? »
- « Liste-moi tous les hooks WordPress qui modifient le comportement de WooCommerce »
- « Comment fonctionne le système de cache custom et où est-il implémenté ? »
- « Quels fichiers JavaScript gèrent les interactions AJAX avec WordPress ? »
- « Y a-t-il des requêtes SQL directes (hors WP_Query) et où se trouvent-elles ? »
Chaque réponse inclut les références exactes (fichiers, lignes) et le contexte nécessaire.
Conclusion : créer sa propre documentation interactive WordPress
Après des mois de tests de solutions existantes (RAG, Dify.ai, vectorisation), j’ai finalement créé une documentation interactive WordPress qui fonctionne parfaitement en combinant :
- Parsing intelligent avec génération de fichiers JSON structurés
- Serveur MCP custom en PHP pour exposer les données WordPress
- Agent Dust connecté pour une interface conversationnelle naturelle
- Mémoire partagée via fichier Markdown collaboratif
Cette approche résout tous les problèmes des solutions classiques : pas de limite de taille, pas de perte d’information, maintenance automatisée, et surtout des réponses précises avec références exactes.
Un exemple concret : ->